Praktikum 7 Avaldised ja päringud
7.1 Andmed
Impordime tänaseks praktikumiks QGISi
- kihelkondade shapefile’i (EKI, Peeter Päll; erineb pisut Maa-ameti ruumiandmete lehel olevast andmestikust; on kasutusel nt eesti murrete korpuses),
- shapefile’i, mis sisaldab andmeid ei ole ja pole eituskonstruktsioonide leviku kohta eesti murretes Andrus Saareste 1955. aasta “Väikese Eesti murdeatlase” põhjal,
- CSV-faili, mis sisaldab andmeid ei ole ja pole suhtelisest sagedusest Eesti murrete korpuses. NB! Kodeering on UTF-8, välju eraldab semikoolon, esimesel real on tulbanimed ning koordinaatide infot failis ei ole. Eesti murrete korpus sisaldab transkribeeritud murdeintervjuude tekste 10 traditsiooniliselt murdealalt. Tekstid on suuremas jaos salvestatud 1960.-1970. aastatel. Korpusest on võimalik teha päringuid nii sõnajärjendite kui ka märksõnade põhjal, et näha näiteks, milline on erinevate keelendite sagedusjaotus eri piirkondade murdetekstides.
Joonis 7.1: Lisatud kihid
Kui soovid võrrelda, kuidas EKI kihelkondade kaart klapib Maa-ameti kihelkondade kaardiga, võid taustaks panna veel WMS-i või WFS-i kaudu Maa-ameti ajaloolise haldusjaotuse kaardi: https://teenus.maaamet.ee/ows/wms-ajalooline-haldus?.
Ei ole ja pole tunduvad eesti keeles paljudes kontekstides ekvivalentsed, samatähenduslikud ja sama funktsiooniga variandid. Sellel varieerumisel on aga ka oma murdetaust: mõned murded eelistavad analüütilist ei ole konstruktsiooni, teised sünteetilist pole konstruktsiooni, ehkki tegemist ei ole selgelt kategooriliste eelistustega (“kasutan ainult üht ja mitte kunagi teist”).
7.2 Avaldised
Avaldised (expressions) on tehted ja vormelid, mille abil hõlpsalt muuta atribuutide väärtusi, luua uusi (virtuaalseid) atribuute või kihte, andmetest alamhulki välja filtreerida, teha statistikat jne. Avaldiste abil saab andmeid QGISis mitmekülgsemalt analüüsida ning visualiseerida.
Avaldisi saab QGISis kasutada mitmes kohas, näiteks
- objektide valimiseks
Select Features by Expressiontööriista abil ,
,
- objektide valimiseks atribuuttabeli alumisest vasakust nurgast
Advanced Filter (Expression) ,
,
- atribuutide muutmiseks ja lisamiseks
Field calculator’is ,
,
- päringute tegemiseks
Query builder’is (Layer Properties → Source → Query Builder) ,
,
- päringute tegemiseks
Database Manager’is (Database → DB Manager) ,
,
- sümbolite, siltide või paigutuse parameetrite muutmisel (
Symbology)
- jne.
Avaldisi saab eeldefineeritud funktsioonide abil koostada niisiis mitmeks erinevaks otstarbeks, vaata ülevaadet QGISi juhendist. Sealjuures saab üht ja sama asja teha sageli erineval moel.
Oleme juba lihtsate avaldistega kokku puutunud, kui arvutasime eelmisel korral digiteeritud polügoonide pindala (6.13): round($area / 10000, 2).
Vaatame sel korral harjutuste ja ülesannete toel lähemalt operaatoreid (Operators), matemaatilisi funktsioone (Math), tingimuslauseid (Conditionals) ning teksti muutmise võimalusi (String).
Operaatorid ja funktsioonid, millega tänases praktikumis kokku puutume, on
-: lahuta ühest väärtusest teine;
>: leia, kas üks väärtus on suurem kui teine (tagastab1(TRUE) või0(FALSE));
>=: leia, kas üks väärtus on suurem kui teine või sellega võrdne (tagastab1(TRUE) või0(FALSE));
IS: mingi (atribuudi) väärtus peab olema mingi kindel väärtus (sama, mis=, tagastab1(TRUE) või0(FALSE));
IS NOT: mingi (atribuudi) väärtus ei tohi olla mingi kindel väärtus (sama, mis!=, tagastab1(TRUE) või0(FALSE));
ILIKE: kas mingi (atribuudi) väärtus vastab mingile kindlale mustrile (tõstutundetu)? (tagastab1(TRUE) või0(FALSE));
OR: operaator VÕI (tagastab1(TRUE) või0(FALSE));
if(tingimus, kuikehtib, kuieikehti): kui kehtib mingi tingimus, määratakse mingi väärtus, kui ei kehti, siis mingi muu väärtus (sama, misCASE ... WHEN ... THEN ... ELSE ... END);
length(tekst): leia mingi teksti/sõne pikkus tähemärkides;
replace(tekst, midaasendada, millegaasendada): asenda tekst või selle mingi osa muu tekstiga;
regexp_replace(tekst, midaasendada, millegaasendada): asenda tekst või selle mingi osa muu tekstiga, kasutades regulaarvaldisi.
7.3 Harjutused avaldistega
Harjutus 1: operaatorid objektide valimiseks
Kasutame valiku tööriista (Select Features by Expression), et teha aktiivseks kõik need kihelkondade polügoonid, millel on midagi kirjutatud tulpa Problem (nt selleks, et hakata parandustega tegelema).
- Kõikide atribuutide/tulpade nimed ja tüübid saab kätte jaotisest
Fields and Values. NuppAll Uniquenäitab atribuudi kõiki eri väärtuseid, nupp10 Samplessellest kuni kümmet esimest eri väärtust. Topeltklikk atribuudi nimel liigutab jutumärkide vahel oleva atribuudi vasakul asuvasse avaldise kasti. Avaldiste kastis viidataksegi topeltjutumärkidega atribuuttabeli mingile tunnusele (= tulbanimele), ühekordsete jutumärkidega mingitele tekstilistele väärtustele (nt kui küsime tulbastParish_idPühalepa kihelkonna rida, siis peaksime kirjutama avaldise"Parish_id"='Phl'või"Parish_id" IS 'Phl').
- Jaotuse
Operatorsalt leiame terve hulga sümboleid, mille abil teha nt arvutustehteid, võrdlustehteid või tekstitöötlust, sh vajamineva operaatoriIS NOT.
- Tahame leida niisiis atribuuttabelist neid ridu, kus tulp
Problemei ole tühi:"Problem" IS NOT NULL.
- Vajutame nupul
Select Features.
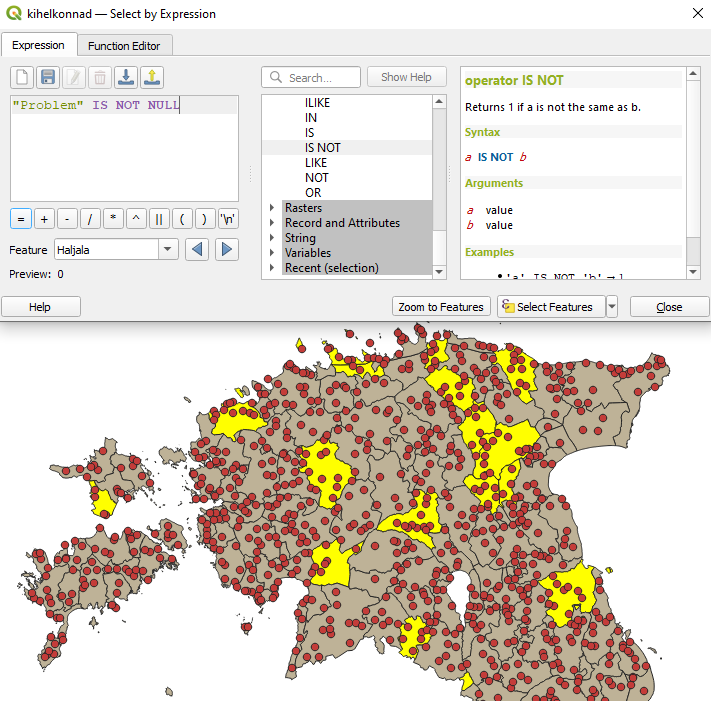
Joonis 7.2: Probleemsed kihelkonnad
Harjutus 2: tingimuslaused uute atribuutide/tunnuste loomiseks
Kasutame väljakalkulaatori tööriista (Field Calculator), et lisada ei ole/pole atlase levikuandmetesse virtuaalne (st ajutine) tekstiatribuut nimega saj19, kus oleks väärtus jah ridadel, kus keelejuhi sünniaeg on väiksem kui aasta 1900, ei, kui keelejuhi sünniaeg on hilisem, ja ei tea, kui keelejuhi sünniaega pole märgitud. Virtuaalse atribuudi lisamiseks valime Field Calculator’is Create a new field → Create virtual field, atribuudi nimeks paneme saj19, atribuudi tüübiks valime Text (string).
- Siin läheb vaja tingimuslauseid jaotises
Conditionals. Kasutame siin funktsiooniif, mille järel sulgude sees komadega eraldatult tuleb anda esmalt tingimus (“Kas tulbasSaKJSyndolev arv on väiksem kui 1900?”), seejärel väärtus juhul, kui tingimus vastab tõele, ning lõpuks väärtus juhul, kui tingimus ei vasta tõele:if("SaKJSynd" < 1900, 'jah', 'ei').
- Meil on aga atribuuttabelis ka sellised read, kus keelejuhi sünniaeg võrdub 0-ga või on NULL, sest see pole teada. Meil oleks oluline märkida ära, et nende puhul me tegelikult sünniaega hinnata ei oska:
if("SaKJSynd" IS 0 OR "SaKJSynd" IS NULL, 'ei tea', if("SaKJSynd" < 1900, 'jah', 'ei')):- Kui tulbas
SaKJSyndon väärtus 0 VÕI polegi midagi (NULL),
- märgi tulpa
saj19väärtus ei tea,
- vastasel juhul
- kui tulbas
SaKJSyndon väärtus, mis on väiksem kui 1900,- märgi tulpa
saj19väärtus jah,
- märgi tulpa
- vastasel juhul väärtus ei.
- kui tulbas
- Kui tulbas
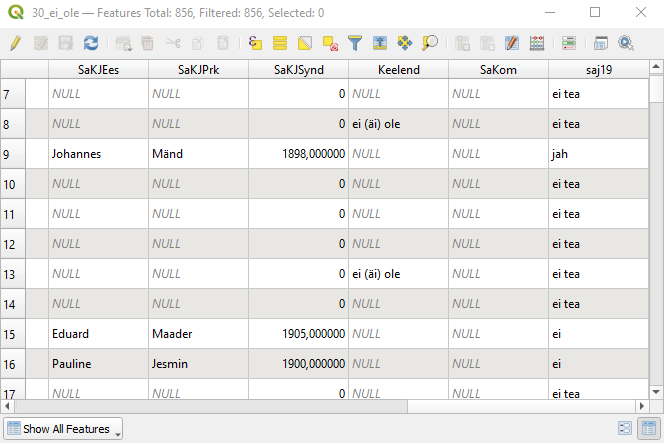
Joonis 7.3: Uue tulba tekitamine
Harjutus 3: tekstiavaldised sümbolite kujundamiseks (1)
Värvime kihelkonnad selle järgi, kui mitu tähte nende nimes on, aga nii, et me ei pea atribuuttabelisse selleks eraldi tunnust looma.
- Valime kihelkondade kihi
Symbologyjaotise altGraduatedjaValuepuhul ühe konkreetse tunnuse nime valiku asemel vajutame lahtri kõrval olevat avaldise sümboliga nuppu .
.
- Kihelkondade nimed on tulbas
Name. Teksti/sõne pikkuse leidmiseks on jaotiseStringall funktsioonlength:length("Name").
- Lisame ka sildid, et kontrollida, kas värvilegend peab paika.
- Alloleva kaardi saamiseks teeme veel mõned kujunduslikud sammud:
Symbology → Graduated → Symbol → Simple Fill:- muudame polügoonide piirjoonte (
Stroke) läbipaistvust 16% peale;
- teeme linnukese
Draw effectsvaliku ette ja vajutame kollasel tähekesel,
- seal omakorda teeme linnukese
Drop Shadowette, valime varju ulatuseks (Offset) 135 kraadi ja 1 mm, udustamise raadiuseks (Blur radius) 2 mm ningBlend modeväärtuseksNormal.
- muudame polügoonide piirjoonte (
Symbology → Labels:- muudame teksti suurust väiksemaks (
Text → Size → 5 points);
- joonistame teksti ümber pooleldi läbipaistva puhverala (
Buffer → Draw text buffer → Opacity = 50%);
- muudame siltide paigutuse nurga alla (
Placement → General Settings → Mode = Free (Angled));
- näitame kõiki (ka kattuvaid) silte (
Rendering → Overlapping labels → Mode = Allow Overlaps without Penalty, vanemates QGISi versioonidesRendering → Show all labels for this layer (including colliding labels)).
- muudame teksti suurust väiksemaks (

Joonis 7.4: Kihelkonnad vastavalt nende nimede pikkusele
Harjutus 4: tekstiavaldised sümbolite kujundamiseks (2)
Toome värvi ja/või sümboliga esile ainult need “ei ole”-“pole” andmestiku punktid, mille asustusüksuse nime alguses või lõpus on Jõe-/-jõe või Järve-/-järve. Teised punktid värvime halliks ja teeme läbipaistvamaks. Need punktid, millel asulanime atribuuttabelis ei ole, jätame jooniselt välja.
- Asendame esmalt ő-sümbolid tulbas
ANIMIõ-tähtedega:- Selleks saame
Field Calculator’is uuendada olemasolevat atribuutiANIMI(Update existing field) regulaaravaldise abil (String → replace):replace("ANIMI", 'ő', 'õ').
- Selleks saame
- Valime nüüd punktide kihi
SymbologyaltCategorizedjaValuepuhul vajutame jälle avaldise sümboliga nuppu.- Saame kasutada näiteks operaatorit
ILIKE:"ANIMI" ILIKE '%jõe%' OR "ANIMI" ILIKE '%järve%'.
- Selles avaldises ütleme, et kujunda mingit moodi ainult need punktid, mille ridadel atribuuttabelis on tulbas “ANIMI” järjend Jõe või jõe (
ILIKEon tõstutundetu) sõna alguses, lõpus või keskel (sümbol%märgib ükskõik mis sümboleid ükskõik kui palju, sh ka 0 sümbolit), samamoodi järve kohta.
- Märgime sellised objektid näiteks tähekestega ja muud punktid, mis avaldisele ei vasta, helehalliks.
- Saame kasutada näiteks operaatorit
- Lisame sama avaldist kasutades ka sildid ainult valitud punktidele:
if("ANIMI" ILIKE '%jõe%' OR "ANIMI" ILIKE '%järve%', "ANIMI", NULL).
- Võime lisada alla veel Maa-ameti fotokaartide WMS-teenusest värvilise reljeefvarjutuse (
6 vreljeef), et vaadata, kas leitud kohanimed ka päriselt veekogude ääres on.
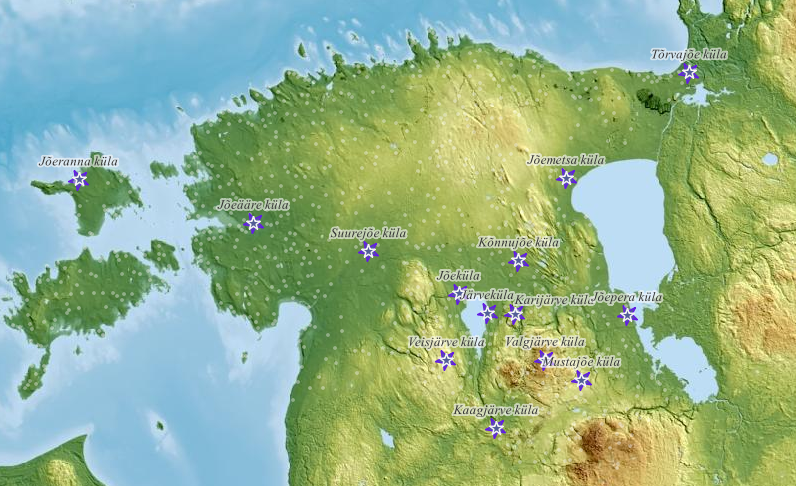
Joonis 7.5: Jõe- ja järvenimelised asulanimed
7.4 Päringud
Lisaks eeldefineeritud funktsioonidele saab QGISis kasutada ka SQL-i päringuid, näiteks:
- Ridade ja tulpade valimine
- SELECT tulp FROM andmestik;
- vali andmestikust ainult üks tulp
- vali andmestikust ainult üks tulp
- SELECT tulp1, tulp2 FROM andmestik;
- vali andmestikust kaks tulpa
- vali andmestikust kaks tulpa
- SELECT DISTINCT tulp FROM andmestik;
- vali andmestikust tulba unikaalsed väärtused
- vali andmestikust tulba unikaalsed väärtused
- SELECT * FROM andmestik;
- vali andmestikust kõik tulbad ja read
- vali andmestikust kõik tulbad ja read
- SELECT * FROM andmestik WHERE tulp = ‘Mingi väärtus’;
- vali andmestikust kõik tulbad ja read, kus tulbas ‘tulp’ on väärtus ‘Mingi väärtus’
- vali andmestikust kõik tulbad ja read, kus tulbas ‘tulp’ on väärtus ‘Mingi väärtus’
- SELECT tulp1, tulp2 FROM andmestik WHERE tulp1 > 50 AND tulp2 ILIKE ‘%St%’;
- vali andmestikust tulbad ‘tulp1’ ja ‘tulp2’ ning ainult sellised read, kus tulp1 väärtused on suuremad kui 50 ja kus tulp2s on lahtris kuskil tähejärjend ‘St’
- vali andmestikust tulbad ‘tulp1’ ja ‘tulp2’ ning ainult sellised read, kus tulp1 väärtused on suuremad kui 50 ja kus tulp2s on lahtris kuskil tähejärjend ‘St’
- SELECT tulp FROM andmestik;
- Muutmine
- UPDATE andmestik SET tulp = ‘Mingi uus väärtus’ WHERE tulp = ‘Mingi vana väärtus’;
- uuenda andmestikku nii, et sea tulba ‘tulp’ väärtuseks ‘Mingi uus väärtus’ nendel ridadel, kus tulba ‘tulp’ väärtus on praegu ‘Mingi vana väärtus’
- uuenda andmestikku nii, et sea tulba ‘tulp’ väärtuseks ‘Mingi uus väärtus’ nendel ridadel, kus tulba ‘tulp’ väärtus on praegu ‘Mingi vana väärtus’
- UPDATE andmestik SET tulp = ‘Mingi uus väärtus’ WHERE id = 8;
- uuenda andmestikku nii, et sea tulba ‘tulp’ väärtuseks ‘Mingi uus väärtus’ sellel real, kus id väärtus on 8
- uuenda andmestikku nii, et sea tulba ‘tulp’ väärtuseks ‘Mingi uus väärtus’ sellel real, kus id väärtus on 8
- UPDATE andmestik SET tulp = ‘Mingi uus väärtus’ WHERE tulp = ‘Mingi vana väärtus’;
- Lisamine
- INSERT INTO andmestik (tulp1, tulp2, tulp3, tulp4) VALUES (‘tulp1 väärtus’, ‘tulp2 väärtus’, ‘tulp3 väärtus’, ‘tulp4 väärtus’);
- sisesta andmestikku üks rida, kus tulpadesse ‘tulp1’, ‘tulp2’, ‘tulp3’ ja ‘tulp4’ lähevad vastavalt väärtused ‘tulp1 väärtus’, ‘tulp2 väärtus’, ‘tulp3 väärtus’ ja ‘tulp4 väärtus’
- sisesta andmestikku üks rida, kus tulpadesse ‘tulp1’, ‘tulp2’, ‘tulp3’ ja ‘tulp4’ lähevad vastavalt väärtused ‘tulp1 väärtus’, ‘tulp2 väärtus’, ‘tulp3 väärtus’ ja ‘tulp4 väärtus’
- INSERT INTO andmestik (tulp1, tulp2, tulp3, tulp4) VALUES (‘tulp1 väärtus’, ‘tulp2 väärtus’, ‘tulp3 väärtus’, ‘tulp4 väärtus’);
- Kustutamine
- DELETE FROM andmestik WHERE tulp = ‘Mingi väärtus’;
- kustuta andmestikust read, kus tulbas ‘tulp’ on väärtus ‘Mingi väärtus’
- kustuta andmestikust read, kus tulbas ‘tulp’ on väärtus ‘Mingi väärtus’
- DELETE FROM andmestik WHERE tulp = ‘Mingi väärtus’;
- Järjestamine
- SELECT tulp1, tulp2, tulp3 FROM andmestik ORDER BY tulp1;
- vali andmestikust ainult tulbad ‘tulp1’, ‘tulp2’ ja ‘tulp3’ ning järjesta uus andmestik ‘tulp1’ väärtuste järgi (vaikimisi väiksemast suuremani või A-st Z-ni)
- vali andmestikust ainult tulbad ‘tulp1’, ‘tulp2’ ja ‘tulp3’ ning järjesta uus andmestik ‘tulp1’ väärtuste järgi (vaikimisi väiksemast suuremani või A-st Z-ni)
- SELECT tulp1, tulp2, tulp3 FROM andmestik ORDER BY tulp1, tulp2;
- vali andmestikust ainult tulbad ‘tulp1’, ‘tulp2’ ja ‘tulp3’ ning järjesta uus andmestik ‘tulp1’ ning siis ‘tulp2’ väärtuste järgi
- vali andmestikust ainult tulbad ‘tulp1’, ‘tulp2’ ja ‘tulp3’ ning järjesta uus andmestik ‘tulp1’ ning siis ‘tulp2’ väärtuste järgi
- SELECT tulp1, tulp2, tulp3 FROM andmestik ORDER BY tulp1;
- Grupeerimine
- SELECT tulp1, tulp2 FROM andmestik GROUP BY tulp1;
- vali andmestikust tulbad ‘tulp1’ ja ‘tulp2’ ning grupeeri andmed ‘tulp1’ unikaalsete väärtuste järgi
- vali andmestikust tulbad ‘tulp1’ ja ‘tulp2’ ning grupeeri andmed ‘tulp1’ unikaalsete väärtuste järgi
- SELECT tulp1, tulp2 FROM andmestik WHERE tulp1 = ‘Mingi väärtus’ GROUP BY tulp2;
- vali andmestikust tulbad ‘tulp1’ ja ‘tulp2’ ning ainult read, kus tulbal ‘tulp1’ on väärtused ‘Mingi väärtus’, grupeeri saadud tabel ‘tulp2’ unikaalsete väärtuste järgi
- SELECT tulp1, tulp2 FROM andmestik GROUP BY tulp1;
7.5 Harjutus päringutega
SQL-i päringuid saab QGISis teha nt DB Manager tööriistaga (ülamenüüs Database → DB Manager). Mõned SQL-i funktsioonid (nt UPDATE) töötavad ainult “päris” andmebaasiformaatidega, nt GeoPackage’i failidega (kui need on ka GeoPackage’ina sisse loetud, mitte lihtsalt vektorfailidena).
DB Manageris valime praegu virtuaalsete kihtide alt kihelkondade polügoonide kihi, valime ülevalt menüüst SQL Window  ja kirjutame kasti päringu (asendame punktiirid sobivate väärtustega).
ja kirjutame kasti päringu (asendame punktiirid sobivate väärtustega).
- Valime kihelkondade andmestikust ainult eestikeelse murrete nimede tulba ja salvestame selle eraldi kihil.
SELECT ... FROM ...;
- Kui tahame uuele kihile saada kaasa ka polügoonide andmeid, peame valima “eraldi tulbana” ka kihi geomeetria, mis on enamasti kujul
geometry:SELECT ..., geometry FROM ...;
- Vajutame Execute, teeme linnukese Load as new layer ette ja vajutame Load.
- Valime kihelkondade andmestikust kõik tulbad, aga ainult need Võru murde kihelkondade read, kus kihelkonna pindala on suurem kui kõikide eesti kihelkondade keskmine pindala.
SELECT ... FROM ... WHERE ... = '...' AND ... > (SELECT AVG(...) FROM ...);
- Leiame murdealade kogupindalad.
SELECT ..., SUM(...) AS pindala FROM ... GROUP BY ...;
7.6 Ülesanded
7.6.1 Ülesanne 1: “ei ole”/“pole” suhtelised sagedused murdekorpuses
Värvime kihelkondade polügoonid selle põhjal, kui palju neis kasutatakse murdekorpuse (!) andmete põhjal protsentuaalselt eituse varianti ei ole (vs. pole). Need suhtelised sagedused on tabelis eiole_pole_mk_props.csv, aga selle tabeliga ei ole seotud mingeid koordinaate. Peame niisiis ühendama tabeli mingi tunnuse alusel (nt kihelkondade nimede järgi) olemasolevate ruumiandmetega.
- Teeme esmalt virtuaalse koopia kihelkondade kihist (nimetame selle nt
kihelkonnad2). Nõnda ei mõjuta see, mida edasi teeme, meie algandmestikku. Kui muudaksime otse kihelkondade kihti, salvestaksime originaalandmed üle. Koopia tegemiseks on palju viise, ent harjutamise mõttes kasutame selleks siin SQLi päringut.Layer → Create Layer → New Virtual Layer: nimetame kihi nimegakihelkonnad2,Queryväljale kirjutameSELECT * FROM kihelkonnadja vajutameAdd;
- Ühendame andmestiku
eiole_pole_mk_propskihigakihelkonnad2. Esmalt kontrollime, kas ühendamine võiks üldse korralikult õnnestuda, st kas mõlemas kihis viidatakse samadele kihelkondadele ühtmoodi. Selleks, et leida kihelkonnad/murrakud, mis on kahele kihile ühised, saab kasutada SQLi päringutSELECT Murrak FROM eiole_pole_mk_props INTERSECT SELECT Parish_id FROM kihelkonnad2;. Selleks, et leida aga kihelkonnad, mida teises andmestikus ei ole, võib kasutada päringutSELECT Murrak FROM eiole_pole_mk_props EXCEPT SELECT Parish_id FROM kihelkonnad2;. Kasutame päringu tegemiseksDB Manageri. Kui oleme vajutanud nupulExecute, väljastatakse alumisse aknasse need murrakute nimed, mis on küll andmestikuseiole_pole_mk_propstulbasMurrak, ent mida ei ole sellisel kujul andmestikuskihelkonnad2tulbasParish_id.
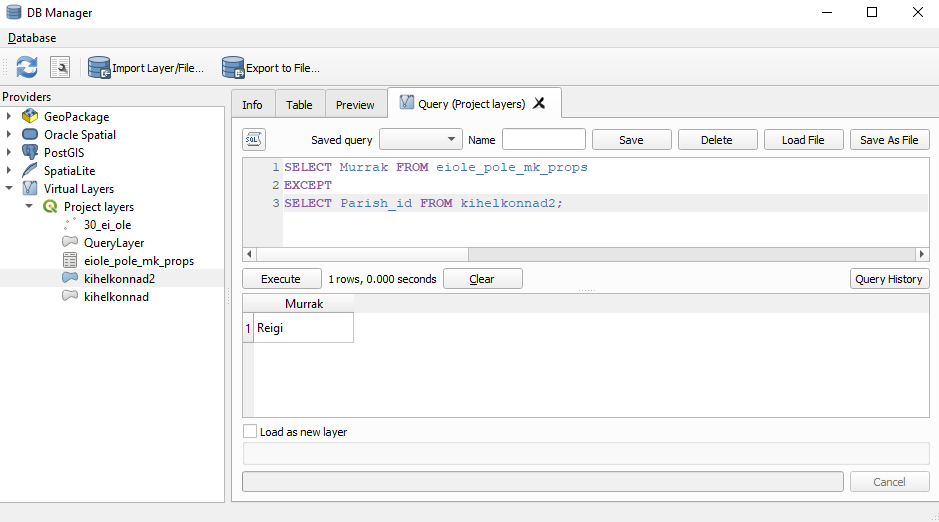
Joonis 7.6: Vigase kihelkonnanime tuvastamine
- Parandame CSV-kihis selle murraku nime, mis ei sisaldu kihelkondade shapefile’is. Kuna CSV-faili atribuute muuta ei saa, lisame kihile uue virtuaalse atribuudi
Murrak2, kus asendame vigase nime õigega (kasutameif-tingimuslauset).
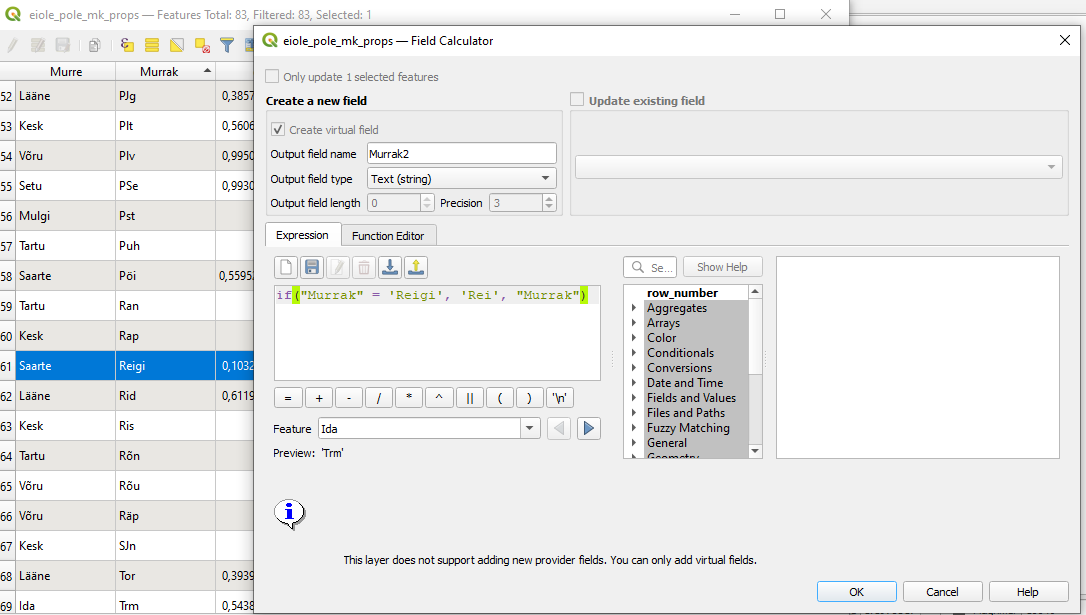
Joonis 7.7: Uue virtuaalse atribuudi loomine
- Lisame kihile
kihelkonnad2ei ole/pole kasutamise sagedusandmed. Kasutame andmestike ühendamiseks vastavaltParish_idjaMurrak2tulpasid.- Teine moodus kihte ühe tunnuse alusel ühendada on nii, kui valime
Processing → Toolbox → Vector general → Join attributes by field value. Erinevus tavaliseJoin-funktsiooniga on selles, et tekib uus kiht (vaikimisi nimegaJoined layer).
- Teine moodus kihte ühe tunnuse alusel ühendada on nii, kui valime
- Värvime ei ole/pole proportsioonide infoga täiendatud kihi
kihelkonnad2polügoonid vastavalt ei ole suhtelisele sagedusele kihelkonnas/murrakus nii, et viirutatult oleksid märgitud ka kihelkonnad, millest murdekorpuse sagedusinfot ei ole (vaikimisi klassifitseerides neid kihelkondi enam üldse ei näidataks). Selleks peab kasutama reeglipõhist sümboloogiat. Nendele kihelkondadele, kust infot on, teeme 5 sagedusklassi (0-0.2, 0.2-0.4, 0.4-0.6, 0.6-0.8 ja 0.8-1.0).
Joonis 7.8: Reeglipõhine polügoonide värvimine
7.6.2 Ülesanne 2: “ei ole”/“pole” murdeatlase levikuandmed
- Lisame joonisele ka murdeatlase punktandmed ning eristame punktide välimuse selle järgi, kas tegemist on ei ole või pole variandiga.
- Kuna praegu on keelendi tulbas igasuguseid variante, nt põle, ei (äi) ole, ole ei (õi), ei (äi, öi) pole, siis peaks esmalt looma ühe binaarse (ainult kahe võimaliku väärtusega) atribuudi, kus oleksid ainult väärtused ei ole ja pole.
- Selleks filtreerime (paremklikk →
Filter) kihist30_ei_olevälja ainult need read, kus keelendi info on olemas ("Keelend" IS NOT NULL) ning lisame selle atribuuttabelisseField Calculator’i abil uue virtuaalse atribuudi/tulba nimegaKeelend2, kuhu paneme väärtuse pole siis, kui keelendi tulbas esineb p-täht, ja ei ole siis, kui ei esine (see tähendab, et ka nt ei pole klassifitseeritakse pole-ks). Kasutameif-tingimuslauset jaILIKE-operaatorit:if("Keelend" ILIKE '%p%', 'pole', 'ei ole').
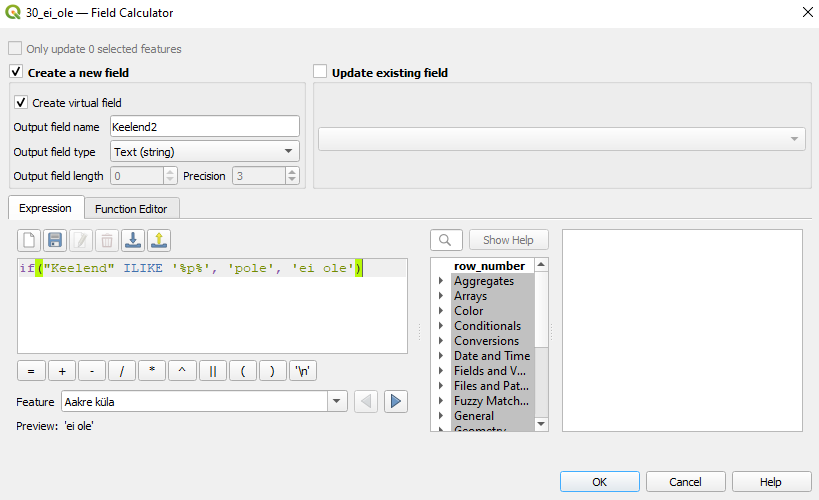
Joonis 7.9: Binaarse virtuaalse tunnuse loomine
- Valime binaarsele keelendile vastava sümboli ja värvi.
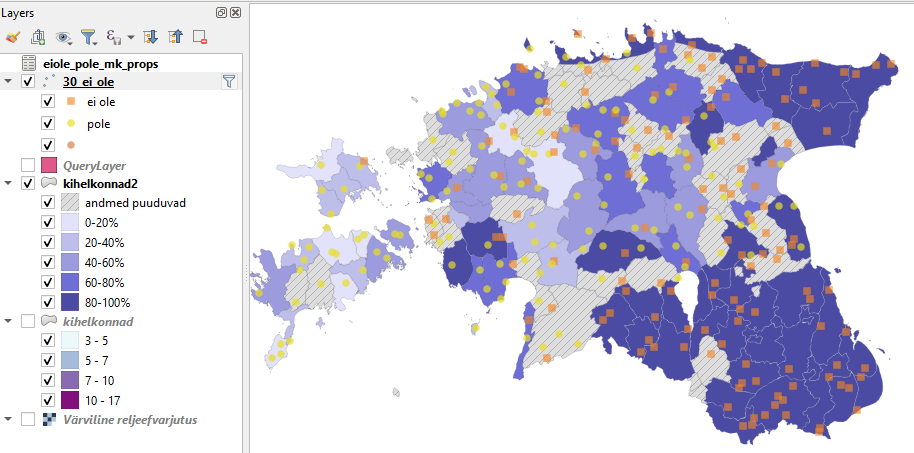
Joonis 7.10: Korpuse ja atlase andmed eituskonstruktsioonide ei ole ja pole sagedusest ja levikust
7.6.3 Ülesanne 3: “ei ole”/“pole” selged eelistused
- Teeme kihist
kihelkonnad2duplikaadi nimegakihelkonnad3(paremklikk →Duplicate Layerja uuel kihil paremklikk →Rename Layer).
- Kasutades reeglipõhist polügoonide värvimist, kuvame kihil
kihelkonnad3värviliselt ainult kihelkonnad, mille puhul ei ole ja pole proportsioonide absoluuterinevus on vähemalt 0,5. Ülejäänud polügoonidele (sh puuduvatele väärtustele) määrame halli värvi.
Joonis 7.11: Suured sageduserinevused
- Nüüd muudame reegleid nii, et kihelkonnad, mille puhul ei_ole ja pole suur vahe on negatiivne (-0,5 või vähem), on punased, ja need, mille vahe on positiivne (0,5 või suurem), on sinised.
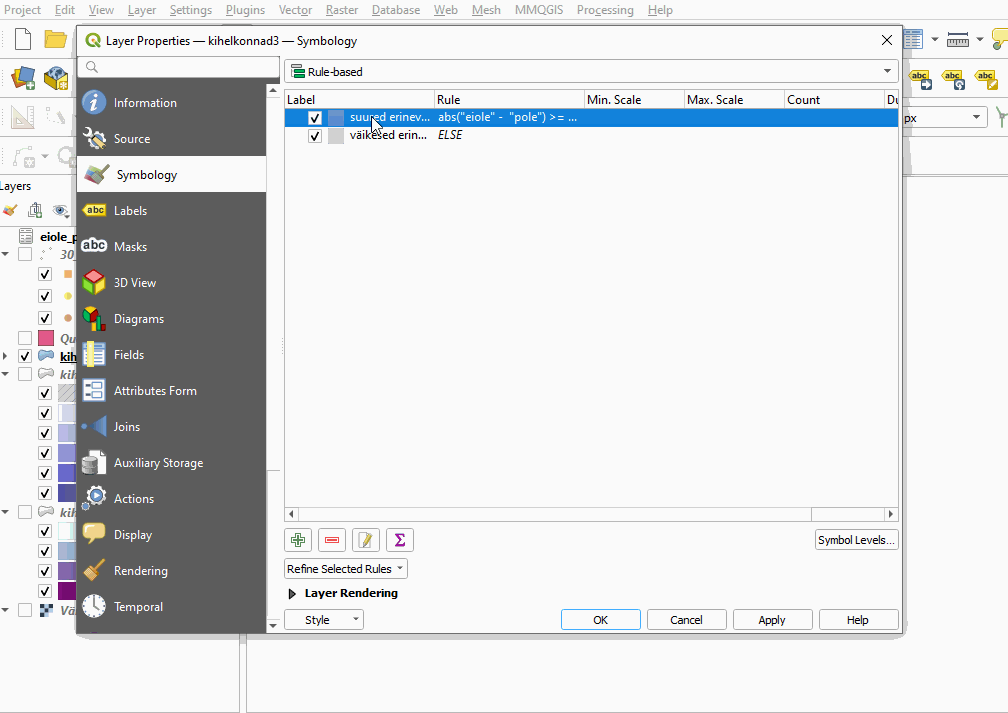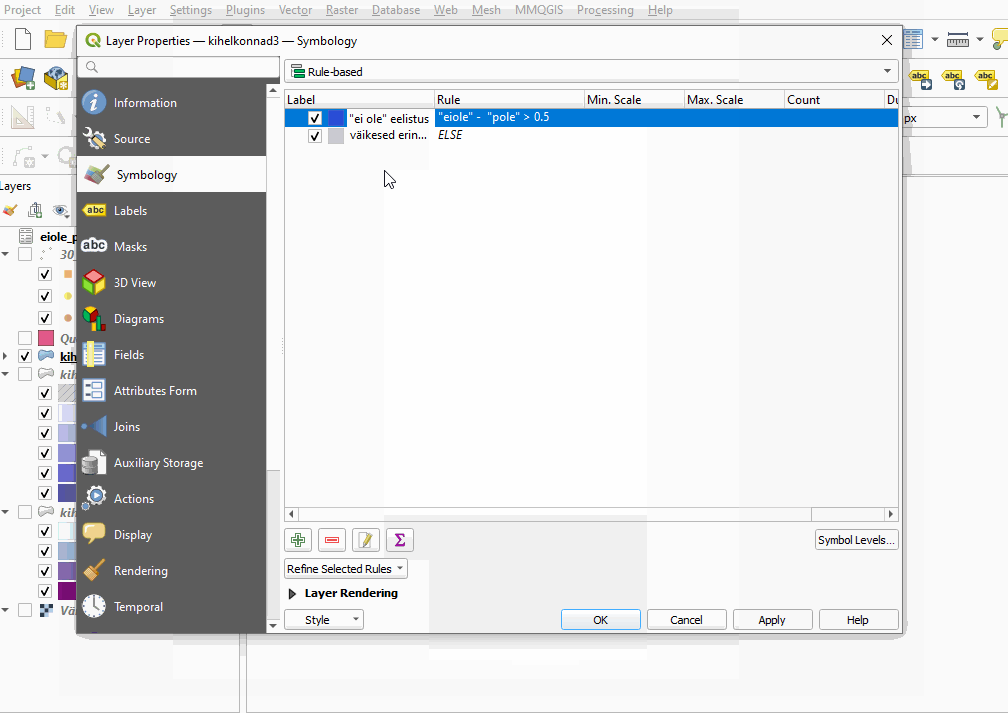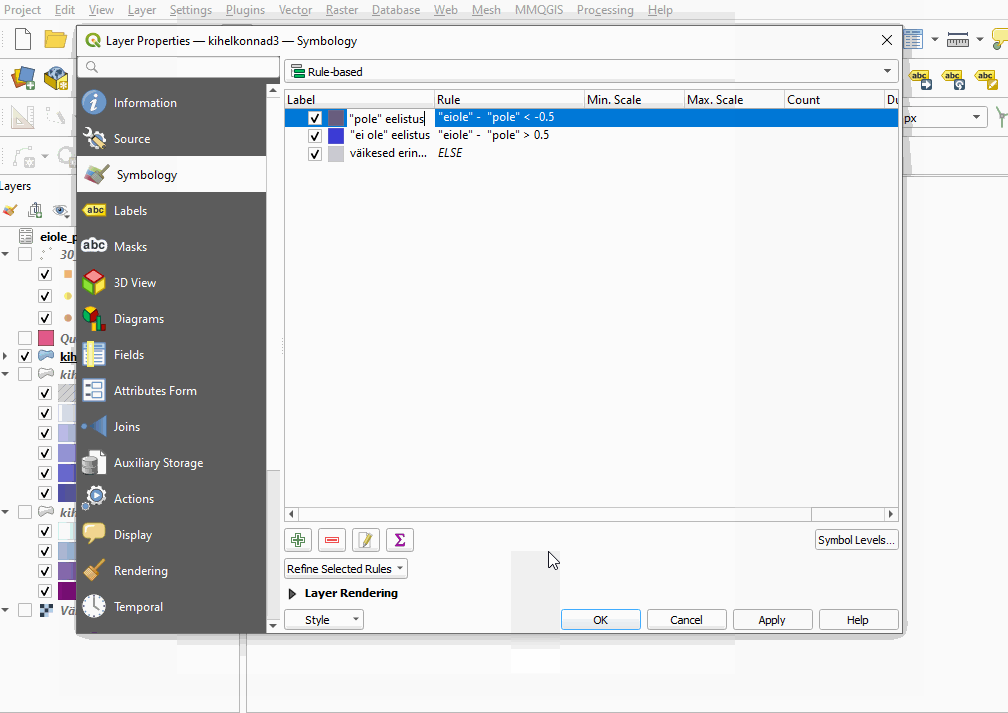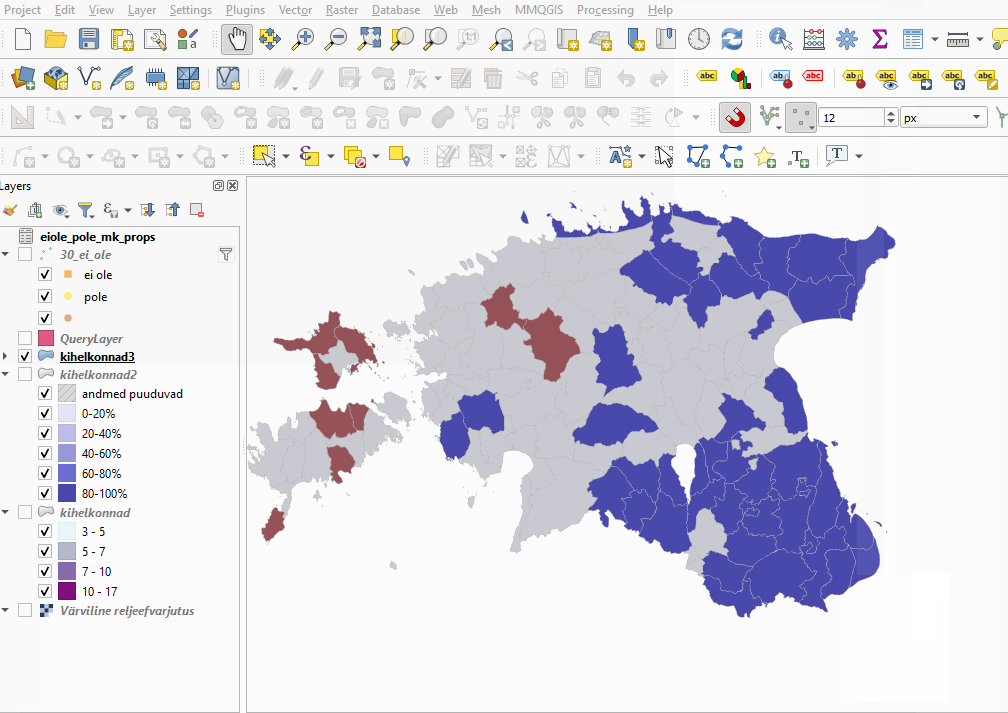
Joonis 7.12: ei ole ja pole konstruktsioonide eelistused murrakutes
7.6.4 Ülesanne 4: tekstiatribuutide muutmine
- Muudame kihil
kihelkonnad3eestikeelsete murrete nimetustes kõik Setu murded Seto murreteks, kasutadesif-tingimuslauset. Salvestame uued nimed uude tulpaMurre.
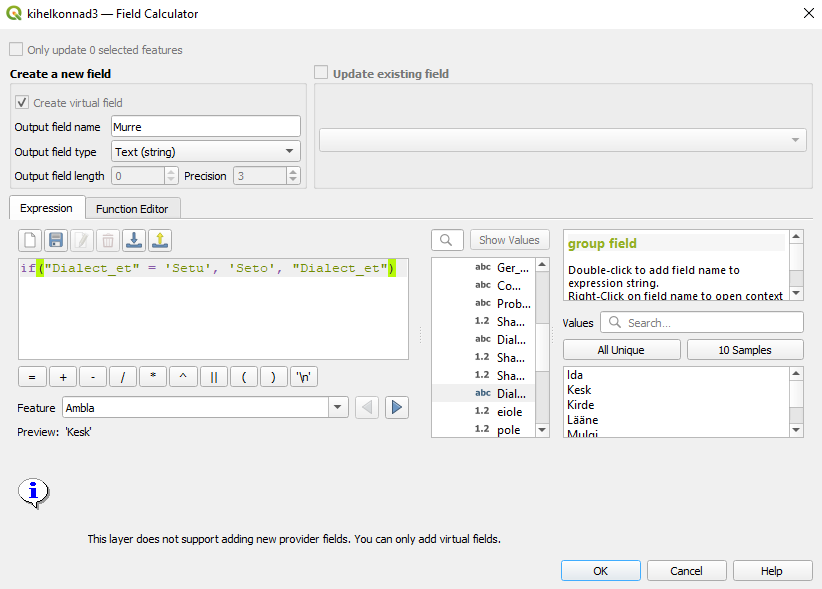
Joonis 7.13: Setu murre Seto murdeks
- Muudame nüüd kihil
kihelkonnad3ingliskeelsete murrete nimetustes kõik Setu murded Seto murreteks, kasutadesCASE-tingimuslauset. Salvestame uued nimed uude tulpaDialect.
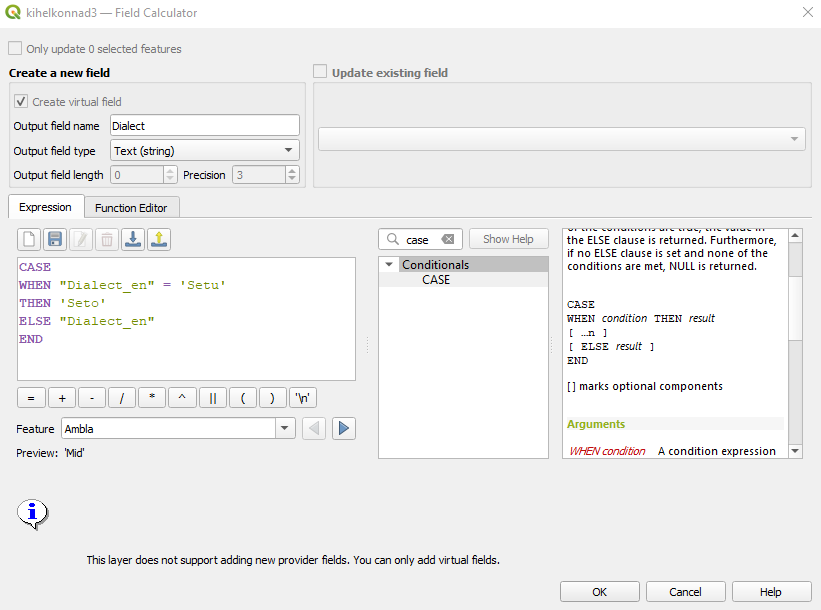
Joonis 7.14: Setu murre Seto murdeks (2)
- Leiame kihil
kihelkonnad3kõik kihelkondade nimed, mille saksakeelne nimi algab lühendiga St. ning muudame lühendi Sankt’iks, kasutades regulaaravaldist. Salvestame uued nimed uude tulpa nimegaSaksakeelne_nimi.
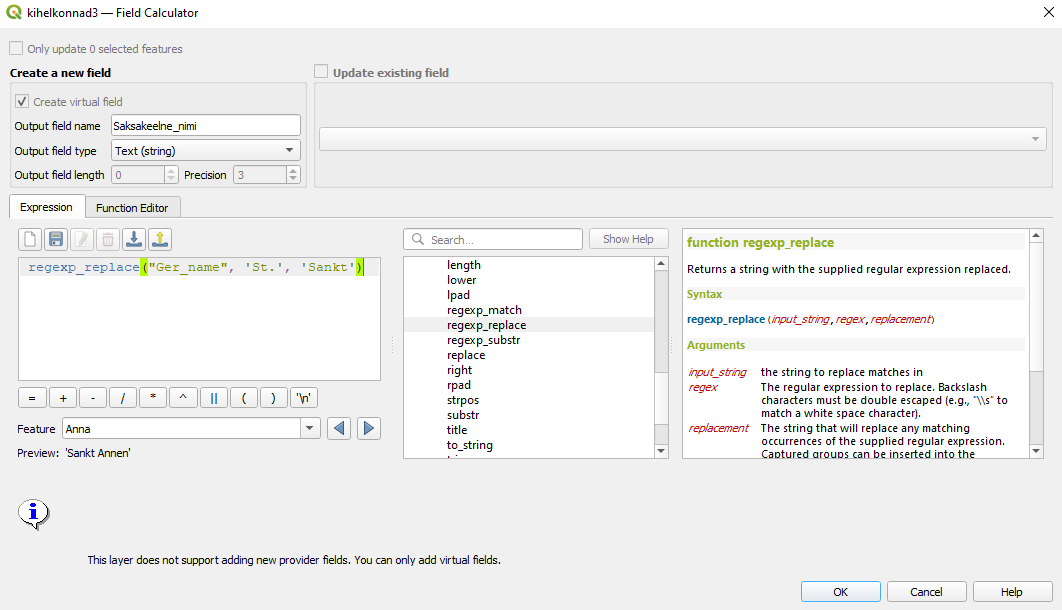
Joonis 7.15: St. muutmine Sankt’iks
- Leiame kõik kihelkonnad, mille nimed lõppevad la-ga (nt Ambla) ja asendame need lõpud uues tulbas nimega “Kihelkond” LA-ga (AmbLA), kasutades regulaaravaldist:
regexp_replace("Name", '(.*)la', '\\1LA'). Siin ütleme, et- tulba
Namekõikides sõnades,
- mis algavad mis iganes sümboliga (nt tähega, numbriga, kirjavahemärgiga, tühikuga)
., - mida esineb ükskõik mitu korda
*(nt Kei, Viga, Amb, Halja)
- ja kus sellele millele iganes mitu iganes korda järgneb järjend la,
- jäta alles see esimene
\\1(ja siin ainus) grupeeritud osa(.*)enne la-d,
- aga grupeeritud osa lõpus asenda järjend la järjendiga LA.
- tulba
Põhimõtteliselt võiksime kasutada DB Manageris ka UPDATE CASE WHERE lauseid, ent kuna ükski meie kihtidest ei ole QGISi jaoks päris andmebaas, siis saame teha DB Manageris ainult päringuid, aga tabelit muuta ei saa. Saame aga eksportida mõne virtuaalse kihi näiteks GeoPackage-formaadis failina ning seda uuesti sisse lugedes saame andmestikku DB Manageris ka SQL-lausete abil muuta.