Praktikum 8 Geograafiline tekstianalüüs
Geograafiline tekstianalüüs on uurimissuund ja metodoloogia, mis ühendab kirjandusteaduste traditsioonilised tekstianalüüsi meetodid ruumianalüüsi ja arvutuslike tekstianalüüsi meetoditega.
Geograafilise tekstianalüüsi nimi on kitsamalt seotud Lancasteri ülikooliga ning nimedega nagu Ian Gregory, Christopher Donaldson, Patricia Murrieta-Flores jt. Ehkki Lancasteri ülikooli projekt Mapping the Lakes: A Literary GIS ei olnud kaugeltki mitte esimene projekt, mis kirjandusteoste kaardistamisega tegeles, oli see üks esimesi, mis süsteemselt tegeles sellega, et demonstreerida, kuidas digiteerimise ja GISi abil saab visualiseerida ja analüüsida (ajaloolisest) struktureerimata tekstist välja kooruvaid mustreid, kohtade eri kujutamisviise ning kohtadega seotud tundmusi, kujutlusi jms.
![*Mapping the Lakes*: kahe poeedi reisikirjeldustes mainitud kohtade võrdlus [@Gregory&Cooper2009]](imgs/14_mappinglakes1.jpg)
Joonis 8.1: Mapping the Lakes: kahe poeedi reisikirjeldustes mainitud kohtade võrdlus (Gregory et al. 2009)
)](imgs/14_mappinglakes3.PNG)
)](imgs/14_mappinglakes4.PNG)
Joonis 8.3: Inglismaa Lake District ehk “järvemaa” piirkond (© User:Nilfanion / Wikimedia Commons / CC-BY-SA)
Joonis 8.4: Inglismaa Lake District ehk “järvemaa” piirkond (© User:Diliff / Wikimedia Commons / CC-BY-SA)
Esimesele projektile Inglismaa Järvemaa piirkonnast järgnesid jätkuprojektid Spatial Humanities: Texts, GIS & Places ja Geospatial Innovation: A Deep Map of the Lake District. Kui esimeses projektis tehti kohtade ja nendega seotu tuvastamisel rohkem käsitööd, siis järgnevates kasutati juba enam tekstide ja keele automaattöötluse vahendeid. Samuti kasutati hilisemates projektides ka muid andmeid (nt rahvastikuandmeid).
![Kohtadest kirjutamine ja maastikud [@Murrieta-Flores2017]](imgs/14_costsurface.png)
Joonis 8.5: Kohtadest kirjutamine ja maastikud (Murrieta-Flores et al. 2017)
![Kohtadest kirjutamine ja maastikud [@Murrieta-Flores2017]](imgs/14_mappinglakes2.PNG)
Joonis 8.6: Kohtadest kirjutamine ja maastikud (Murrieta-Flores et al. 2017)
Praegu võib geograafilise tekstianalüüsi keskmeks pidada niisiis korpuslingvistiliste meetodite kasutamist, ent laiemalt võib sellesse valdkonda lugeda mis tahes kohtadega seotud kirjandusliku või ajaloolise teksti analüüsi ja visualiseerimise, nn literary GIS või literary mapping.
![Literary Mapping in the Digital Age [@Cooper&Donaldson&Murrieta-Flores2016] (vaata [sisukorda](https://books.google.ee/books?id=v_EyDAAAQBAJ&printsec=frontcover&hl=et#v=onepage&q&f=false))](imgs/14_literarymappingbook.PNG)
Joonis 8.7: Literary Mapping in the Digital Age (Cooper et al. 2016) (vaata sisukorda)
Geograafilises tekstianalüüsis on prominentsel kohal tekstides mainitud kohanimed ja nendega seostuv:
- Mis kohtadest tekstides räägitakse?
- Kuidas tekstides nendest kohtadest räägitakse?
- Mida räägitakse tekstides nende kohtadega seotud objektide ja nähtuste kohta?
Geograafiline tekstianalüüs on seega üks tekstide kauglugemise (distant reading) tehnikatest, mille abil tuvastada tekstidest mustreid.
Humanitaarteadustes on meetodit kasutatud põhiliselt ajalooliste (st enne 20. sajandit kirjutatud) tekstide analüüsil, eeskätt ilmselt autoriõiguste tõttu, ent sellel on suur ühisosa ka tänapäevaste avalike tekstide analüüsiga.
Ajalooliste tekstide puhul lisandub analüüsi sageli teoste digiteerimise protsess (nt käsitsi sisestamine või tärktuvastus), mida võivad oluliselt komplitseerida aja jooksul toimunud muutused näiteks
- kirjastamiskonventsioonides,
- trükiformaatides,
- keeles,
- kirjaviisis,
- haldusjaotuses jne.
8.1 Sammud
Geograafilises tekstianalüüsis on tüüpiliselt 3 põhisammu.
- Tekstis viidatud kohanimede tuvastamine.
- Kohanimesid võib tuvastada mõistagi käsitsi, teksti lähilugemisel, aga üha enam kasutatakse tänapäevaseid loomuliku keele töötluse vahendeid (automaatne nimetuvastus, Named Entity Recognition). Üksikute tekstide puhul tagab käsitsi otsimine kindlasti parema kvaliteedi, ent suuremate tekstikorpuste puhul läheb see liiga aeganõudvaks ja ressursimahukaks.
- Probleeme:
- kohtadele ei ole alati viidatud konkreetsete kohanimedega (nt Anne sauna taga, kaks kilomeetrit Elvast läände, see küla, kust me läbi sõitsime); sageli seda aga ignoreeritakse põhjenduse toel, et konkreetsete kohanimedega tehakse veidi teisi asju kui ümberütlemistega: luuakse korraga tahtlikult narratiivset JA geograafilist ruumi.
- probleemid metonüümiaga (nt saab kohanime märgendi hoopis organisatsioon mingi riigi valitsuse, meeskondade vmt puhul, Itaalia võttis vastu otsuse…, Eesti kaotas 1-8);
- digiteerimise käigus tekib alati vigu, ükskõik kas tärktuvastuse või käsitsi sisestamisega;
- ajaloolistes kohanimedes palju varieeruvust, seal esinevad kohanimed ei pruugi sisalduda ka andmetes, mille peal automaatse analüüsi vahendid on treenitud;
- kui oskad veidi skripte kirjutada, saab nimetuvastust omakorda täiendada reeglitega (nt määra konstruktsioonid “X talu” alati kohanimedeks).
- kohtadele ei ole alati viidatud konkreetsete kohanimedega (nt Anne sauna taga, kaks kilomeetrit Elvast läände, see küla, kust me läbi sõitsime); sageli seda aga ignoreeritakse põhjenduse toel, et konkreetsete kohanimedega tehakse veidi teisi asju kui ümberütlemistega: luuakse korraga tahtlikult narratiivset JA geograafilist ruumi.
- Kohanimesid võib tuvastada mõistagi käsitsi, teksti lähilugemisel, aga üha enam kasutatakse tänapäevaseid loomuliku keele töötluse vahendeid (automaatne nimetuvastus, Named Entity Recognition). Üksikute tekstide puhul tagab käsitsi otsimine kindlasti parema kvaliteedi, ent suuremate tekstikorpuste puhul läheb see liiga aeganõudvaks ja ressursimahukaks.
- Tuvastatud kohanimede ehk toponüümide sidumine koordinaatidega.
- Enamasti kasutatakse selleks koordinaatidega varustatud kohanimeloendeid (gazetteer) või kohanimeandmebaase (nimeüksuste vastete leidmine ehk Named Entity Matching).
- Probleeme:
- ühe ja sama kohanimega võib viidata mitmele kohale, tuleks lahendada viitesuhted. Selleks võib alati valida näiteks kõige tõenäolisema viite, täpsustada piirkonda või ka käsitsi õige viite määrata;
- kui oskad veidi skriptida, saab siingi kasutada samuti mingeid reegleid ja statistilisi tõenäosusi (nt Lisbon või Berlin viitavad üldiselt tõenäolisemalt Euroopa kohanimedele, aga Ameerika kirjanike puhul või USA idarannikust rääkides USA samanimelistele väikelinnadele).
- ühe ja sama kohanimega võib viidata mitmele kohale, tuleks lahendada viitesuhted. Selleks võib alati valida näiteks kõige tõenäolisema viite, täpsustada piirkonda või ka käsitsi õige viite määrata;
- Enamasti kasutatakse selleks koordinaatidega varustatud kohanimeloendeid (gazetteer) või kohanimeandmebaase (nimeüksuste vastete leidmine ehk Named Entity Matching).
- Mainitud kohtade ja nendega seotu analüüsimine, tõlgendamine ja visualiseerimine.
- Identifitseeritud kohtade mainimissagedusi võib võrrelda näiteks rahvastikunäitajatega (kas tihedamini asustatud kohti mainitakse ka rohkem? kas kohtade sündimus- või suremusnäitajad korreleeruvad nende mainimiste sagedusega?), muude ajalooliste, etnograafiliste vm andmetega. Aga võib ka analüüsida seda, mis kontekstis kohanimesid on tekstides mainitud, näiteks mis emotsioonidega seoses, milliste omadussõnadega seoses jne.
- Siin võib kasutada muu hulgas korpuslingvistilisi meetodeid (nt sagedasti koosesinevate sõnapaaride ehk kollokatsioonide tuvastamine), ühisloomet (nt lastakse inimestel mingeid kohtadega seotud tekstilõike mingil alusel hinnata või märgendada), aga loomulikult ka kvalitatiivset analüüsi.
- Analüüsi käigus selgub ka, milliseid osi tekstikorpusest tuleb n-ö lähilugeda ja milliste osadega saab hakkama ka kauglugemise teel.
- GISi võib kasutada selles etapis põhimõtteliselt ka lihtsalt visualiseerimiseks, aga on ka palju võimalusi põhjalikumaks analüüsiks.
Kaht esimest sammu ehk kohanimede tuvastamist ja eraldamist tekstist ning nende koordinaatidega sidumist nimetatakse kokkuvõtvalt ka geoparsimiseks (geoparsing). Geoparsimine on seega laiem mõiste kui asukohamärgistamine või geokodeerimine, kuna tegeleb ka kohanimede tuvastamisega tekstist ning samuti ebamäärasemate kohaviidete tuvastamise ning viitesuhete lahendamisega.
![Geoparsimine ühendab kohanimede tuvastamise ja koordinaatidega sidumise [@Grittaetal2018]](imgs/14_geoparsing.png)
Joonis 8.8: Geoparsimine ühendab kohanimede tuvastamise ja koordinaatidega sidumise (Gritta et al. 2017)
8.2 Ressursid
Geoparsitud tekstikogusid ei ole väga palju. Seega tuleb huvipakkuvate tekstidega teha läbi kõik ülal nimetatud sammud ise. On mõned valmislahendused, kuhu lihtsustatult öeldes läheb tekst sisse ja välja tuleb geoparsitud fail, milles on eraldatud kohanimed ja määratud neile koordinaadid.
- Näiteks võib kasutada Edinburgh Geoparserit (jookseb ainult Macil ja Linuxil, aga Linuxi virtuaalmasina abil ka Windowsis; juhend kasutamiseks siin), mis kasutab geoparsimisel kontekstilist infot, et leida tekstist kohanimed ning määrata neile õiged koordinaadid. On olemas ka online testversioon: http://jekyll.inf.ed.ac.uk/geoparser/. Edinburgh Geoparser kasutab muu hulgas GeoNamesi koordinaatide jm infoga varustatud üldist kohanimeloendit (sisaldab ka nt u 15 000 Eesti kohanime).
- Geocode.xyz
- CamCoder
- DBpedia Spotlight
- GEOLocate veebiparser on pigem geokodeerija (NB! failiformaat)
Eri geoparserite võrdlemiseks võib kasutada nt EUPEG Java-rakendust.
8.3 Eesti keele geoparsimine
Ülal nimetatud ressursse saab mingil määral kasutada ka eesti keele jaoks, ent eesti keele puhul raskendab kohanimede tuvastamist oluliselt erinevate käändevormide kasutamine (nt Tartu, Tartus, Tartusse).
Eesti keele automaatanalüüsi tööriistade kõige terviklikum komplekt sisaldub Pythoni EstNLTK teegis, mille kaudu on võimalik kasutada nii nimetuvastajat kui ka morfoloogilist analüsaatorit. Nende kasutamiseks tuleb aga osata pisut Pythoni skripte kirjutada (baasasjad saab üpris lihtsa vaevaga omandada nt siit), nimetuvastuse kasutamise juhendi leiab siit.
EstNLTK nimetuvastaja eristab kolme põhitüüpi nimesid:
- isikunimed (
PER), - kohanimed (
LOC), - organisatsiooninimed (
ORG).
Samu tööriistu, mida EstNLTK teegis, kasutatakse ka nimetuvastuse demorakenduses (kuni 5000 tähemärgi pikkusele tekstile) https://ner.tartunlp.ai/. Ajalooliste tekstide nimetuvastuseks arendatud tööriistade prototüübid on kättesaadavad lehel https://github.com/soras/vk_ner_lrec_2022.
Tuvastatud kohanimede algvormid saab omakorda saata näiteks Maa-ameti geokodeerimise teenusesse, et siduda kohanimed koordinaatidega. Võib kasutada ka QGISi geokodeerimise tööriistu (nt Batch Nominatim geocoder’it või mõnd paljudest pistikprogrammidest).
Geoparsimiseks ongi lisaks valmislahendustele oluliselt laialdasemad võimalused erinevates programmeerimiskeeltes (nt Pythonis, Bashis, JavaScriptis). Pythonil on nt geoparsimise teegid Mordecai ja geoparsepy, mis võtavad sisendiks teksti ja väljastavad kohanimed koos koordinaatidega. Samuti kasutavad Pythonit suurem osa ülal nimetatud “valmis” geoparseritest.
8.4 Harjutus
Kasutame geograafilise tekstianalüüsi näitlikustamiseks Riigikogu istungite stenogramme. Selle praktikumi jaoks oleme kraapinud veebist nende istungite protokollid, mis on toimunud vahemikus 01.01.2020 ja 06.11.2023.
Joonis 8.9: Riigikogu istungite stenogrammid veebilehel
Kõik protokollid on Moodle’is praktikumi materjalide kaustas eraldi alamkaustas nimega stenogrammid2023.zip. Samuti on materjalide hulgas kraapimiseks kasutatud R-i skript.
Ülesandes
- leiame, milliseid kohanimeüksusi on mingi istungi protokollis mainitud;
- analüüsime, milline on kohanimeüksust sisaldava tekstikatkendi meelsus: kas tekst on pigem positiivne, negatiivne või neutraalne;
- puhastame andmestiku;
- geokodeerime kohanimeüksused;
- visualiseerime andmeid.
8.4.1 Kohanimeüksuste tuvastamine ja tekstikatkendite meelsuse tuvastamine
Kohanimeüksuste automaatseks tuvastamiseks ning nende vahetu konteksti eraldamiseks tekstist kasutame EstNLTK analüüsivahendeid. Selleks, et Pythoni installimiselt ning skriptide kirjutamiselt aega kokku hoida, kasutame praktikumis Google Colabi, mille kaudu saame jooksutada juba valmis kirjutatud skripti. Kui soovid eesti keele automaattöötluse kohta rohkem õppida, on suureks abiks EstNLTK õppematerjalid (kaustas tutorials) ja TÜ kursus “Eesti keele töötlus Pythonis”.
Meelsusanalüüsiks kasutame siin Eesti Keele Instituudi emotsioonidetektorit, mille aluseks olev Pythoni kood on üleval GitHubi lehel https://github.com/EKT1/valence/. Sama kausta materjalid on ka Moodle’is failis valence-master.zip. Emotsioonidetektori kohta saad lugeda artiklist Pajupuu, Hille; Altrov, Rene; Pajupuu, Jaan (2016). Identifying polarity in different text types. Folklore. Electronic Journal of Folklore, 64, 25−42. Olgu öeldud, et tegemist on üsna vana tööriistaga, tänapäeval saaks ilmselt täpsema tulemuse paremate keelemudelite abil.
Koodi jooksutamiseks vajuta koodiplokkide vasakus servas oleval noolekesel. Kui midagi skripti jooksutamisel ei tööta, on praktikumi materjalides kaasas ka ühe näidisfaili (202203011000.csv) analüüsid (kaustas kohanimed_valmis).
| kohanime_vorm | kohanime_lemma | kontekst | meelsus |
|---|---|---|---|
| Euroopas | Euroopa | Riigikogu liikmeid , kes soovivad üle anda eelnõusid või arupärimisi . Palun Riigikogu kõnetooli Helir-Valdor Seederi . Head kolleegid ! Euroopas käib laiaulatuslik sõda , hävitatakse Ukraina riiki , tapetakse süütuid inimesi . Selle juures on mul siiski hea meel tõdeda | positive |
| Ukraina | Ukraina | anda eelnõusid või arupärimisi . Palun Riigikogu kõnetooli Helir-Valdor Seederi . Head kolleegid ! Euroopas käib laiaulatuslik sõda , hävitatakse Ukraina riiki , tapetakse süütuid inimesi . Selle juures on mul siiski hea meel tõdeda , et Eesti inimesed ja Eesti | positive |
| Eesti | Eesti | sõda , hävitatakse Ukraina riiki , tapetakse süütuid inimesi . Selle juures on mul siiski hea meel tõdeda , et Eesti inimesed ja Eesti ettevõtjad on olnud väga tublid , kaastundlikud , osavõtlikud ja aktiivsed ning panustanud rahaliselt ja humanitaarabiga Ukraina | positive |
| Eesti | Eesti | Ukraina riiki , tapetakse süütuid inimesi . Selle juures on mul siiski hea meel tõdeda , et Eesti inimesed ja Eesti ettevõtjad on olnud väga tublid , kaastundlikud , osavõtlikud ja aktiivsed ning panustanud rahaliselt ja humanitaarabiga Ukraina toetamisse . See | positive |
| Ukraina | Ukraina | Eesti inimesed ja Eesti ettevõtjad on olnud väga tublid , kaastundlikud , osavõtlikud ja aktiivsed ning panustanud rahaliselt ja humanitaarabiga Ukraina toetamisse . See on ääretult vajalik , sest osaleda nii mastaapses sõjas on ülimalt kulukas . Ülimalt kulukas ka Ukraina | positive |
| Ukraina riigile | Ukraina riik | Ukraina toetamisse . See on ääretult vajalik , sest osaleda nii mastaapses sõjas on ülimalt kulukas . Ülimalt kulukas ka Ukraina riigile ja rahvale . Me peame praegu olema nendega solidaarsed ja neid igati aitama , arvestades meie võimalusi . Ja | positive |
Skripti väljundiks on fail istung.csv, kus on tabelkujul
- kohanimeüksus sellisel kujul, nagu see tekstis esineb (tulp
kohanime_vorm);
- kohanimeüksuse algvorm (tulp
kohanime_lemma), mitmesõnalise kohanimeüksuse puhul on lemmatiseeritud ainult nimeüksuse viimane sõna (ntTallinna linn);
- kontekst ehk 20 sõna kohanimest vasakule ja paremale (tulp
kontekst);
- kontekstile määratud meelsuse hinnang (tulp
meelsus).
Loeme tabeli Excelisse või muusse tabeltöötlusprogrammi:
- Data → From Text/CSV → File Origin: UTF-8, Delimiter: Tab → Transform Data → vajuta Use First Row as Headers → Close & Load).
Hindame nimetuvastuse kvaliteeti. On teada, et automaatne nimetuvastus töötab kõige paremini isikunimede tuvastamisega, kohanimede ja organisatsioonidega on sel rohkem raskusi.
Võime andmeid pisut käsitsi puhastada ja korrastada. Kustutame tabelist read, kus nimetuvastus on eksinud (nt Facebook, Euroopa Liit), parandame kohanimede lemmasid (nt pai → Paide).
Salvestame Exceli tabeli nimega istung.xlsx.
8.4.2 Tekstikatkendi meelsuse tuvastamine Excelis
EKI emotsioonidetektor oli kasutatav ka MS Exceli laiendusena (Add-in), ent see ei pruugi uuemates Exceli versioonides töötada ning laiendus ei ole enam veebist allalaaditav.
Katsetame.
Laadime lehelt http://peeter.eki.ee:5000/applications/list alla faili valence.xlam.
Otsime Excelist üles File → Options → Add-ins → Manage Excel Add-ins → Go → Browse, otsime üles faili valence.xlam (kaasas ka praktikumi materjalidega).
Kirjutame Excelis tabeli uude tulpa =Valence.TestBayes() ja sulgude vahele lahtri viite, milles on tekst (nt =Valence.TestBayes(C2)). Kontrollime, kas tulemused vastavad Pythoni skriptiga saadud tulemustele.
8.4.3 Koordinaatide lisamine (geokodeerimine)
Nüüd peame saama oma tabelile koordinaadid. Selleks võiksime proovida põhimõtteliselt kasutada ka Maa-ameti geokodeerimise teenust, aga kuna teame, et meie tabelis on palju ka välisriikide kohanimesid, ei oleks sellest väga palju kasu. Katsetame niisiis hoopis QGISi geokodeerijat.
Esmalt salvestame xlsx-faili csv-na, nt nimega istung_parandatud.csv. Geokodeerimise jaoks oleks vaja, et faili kodeering oleks UTF-8.
Seejärel
- avame QGISi,
- otsime sobiva aluskaardi ja CRS-i,
- laadime csv-faili QGISi,
- valime
Processing → Toolbox → Vector general → Batch Nominatim geocoder,Input layeron csv-faili kiht, mille just laadisime,Address fieldon kohanime_lemma.
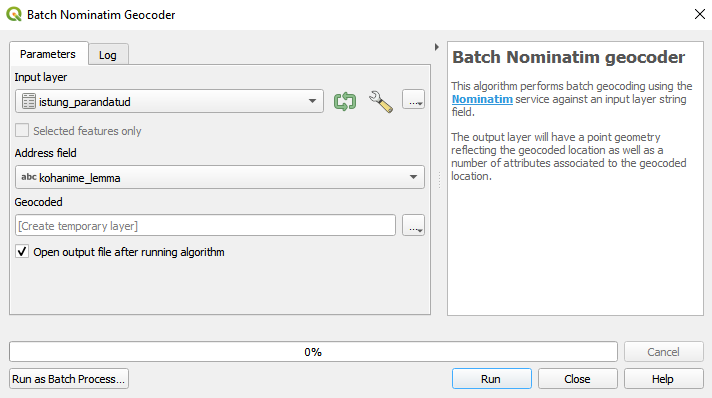
Joonis 8.10: Tuvastatud kohanimede geokodeerimine QGISis
Nimetame kihi Geocoded ümber nimega istungi_kohad.
8.4.4 Visualiseerimine
Mainimiste arv
Vaatame esmalt, milliseid kohti ja kui palju mainiti. Selleks on teatavasti mitu võimalust:
- muudame punktide läbipaistvust (rohkem mainitud kohad jäävad tumedamalt);
- valime
SymbologyjaotisesSingle symbolasemelPoint ClustervõiPoint Displacement;
- valime
SymbologyjaotisesHeatmap, valime sobiva värvipaleti ja -skaala.
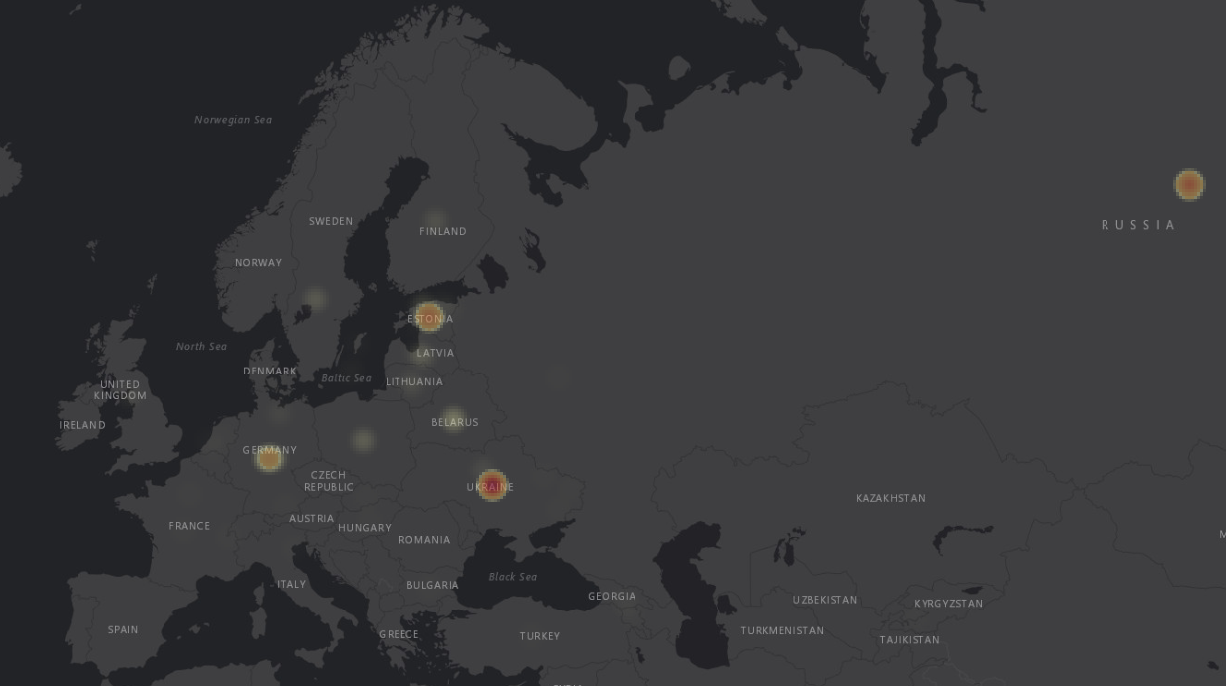
Joonis 8.11: Stenogrammis mainitud kohanimede heatmap
Võime ka teha uue kihi, kus loeme kokku, kui mitu korda üht nime mainitakse, ja visualiseerida mainimiste arvu näiteks punkti suuruse abil. Selleks valime Database → DB Manager → SQL Window ja päringu aknasse kirjutame
SELECT kohanime_lemma, COUNT(kohanime_lemma) AS arv, geometry
FROM istungi_kohad
GROUP BY kohanime_lemma;Vajutame Execute, teeme linnukese kasti Load as new layer ette ja vajutame Load. Uuel kihil vajutame Size paremas ääres kastikest, valime Expression → Edit ja kirjutame avaldiseks log10("arv")*10. Logaritmimine vähendab erinevusi suurt arvude vahel ja toob esile erinevusi väiksemate arvude vahel.
Emotsioonid
Kasutame punktide asemel diagramme, et visualiseerida, kui suur protsent mingi koha mainimistest olid positiivses, negatiivses ja neutraalses kontekstis. Selleks tuleb esmalt teha kiht, kus oleme kokku lugenud iga koha iga emotsiooni mainimiste arvu ja pannud selle eraldi tulpadesse.
Database → DB Manager → SQL Window ja päringu aknasse kirjutame
SELECT kohanime_lemma, geometry,
SUM(CASE WHEN meelsus = 'positive' THEN 1 ELSE 0 END) AS positive,
SUM(CASE WHEN meelsus = 'negative' THEN 1 ELSE 0 END) AS negative,
SUM(CASE WHEN meelsus = 'neutral' THEN 1 ELSE 0 END) AS neutral
FROM istungi_kohad
GROUP BY kohanime_lemma; - Uue tekkinud kihi
Symbologyjaotises valimeSingle symbolasemelNo symbols.
- Lisame pirukadiagrammid (
Diagrams → Pie Chart),- atribuutideks valime tulbad positive, negative ja neutral,
- neile kategooriatele valime sobivad värvid,
- muudame diagrammid veidi läbipaistvamaks (
Rendering → Opacity)
- ja diagrammide suuruseks määrame
Size → Scaled size,Attributeväärtuseks"positive"+"negative"+"neutral"
- ja valime sobiva skaala, arvestades kõige sagedamini mainitud koha mainimiste arvu ja kõige harvemini mainitud kohtade arvu.
- paneme diagrammid punktide koha peale:
Placement → Over point.
- atribuutideks valime tulbad positive, negative ja neutral,

Joonis 8.12: Positiivsete, negatiivsete ja neutraalsete mainimiste osakaalud
Teine variant sama tulemuseni jõudmiseks oleks
- teha topeltklikk kihil istungi_kohad,
- kaotada
Symbologyjaotises ära tavalised punktikesed (No symbols),
- jaotises
DiagramsvalidaPie Chart(ja teha linnuke valikuEnable diagramette),
- seal omakorda
Attributesjaotises lisadaAssigned attributesaknasse kolm avaldist, mis loeksid kokku iga kohanime lemma esinemiskorrad juhul, kui 1) meelsuse tulbas on väärtus positive, 2) meelsuse tulbas on väärtus negative, 3) meelsuse tulbas on väärtus neutral:count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='positive')
count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='negative')
count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='neutral')
- diagrammide
Sizejaotises validaScaled size→Attributeväärtuseks kirjutada avaldiscount("kohanime_lemma", group_by:="kohanime_lemma"), Maximum value määrataFindnupu abil,Sizeväärtuseks määrata nt 15 ning suurendada ka väikeste diagrammide suurust (nt 2 peale).
Sellisel juhul aga tuleb iga muudatust tehes (nt sektorite värvi, diagrammide suurust, läbipaistvust vm-d muutes) diagrammide aluseks olevad andmed iga kord uuesti genereerida ning seetõttu võtab muudatuste nägemine kauem aega.
Määrame lõpuks ka kohanimedele sildid, mis tuleksid nähtavale alles siis, kui oleme piisavalt sisse suuminud.
Symbology → Labels → Single labels → Rendering → Scale Dependent Visibility. Valime ka Overlapping labels → Allow Overlaps without Penalty, et näidata kõiki silte.