Praktikum 15 Geograafiline tekstianalüüs (2)
Tänases praktikumis tegeleme geograafilise tekstianalüüsiga, katsetades eesti keele automaattöötluseks loodud vahendeid. Nagu eelmises praktikumis mainitud, sisaldub selleks kõige põhjalikum tööriistade komplekt Pythoni EstNLTK teekides.
Kasutame geograafilise tekstianalüüsi näitlikustamiseks Riigikogu istungite stenogramme. Selle praktikumi jaoks oleme kraapinud veebist nende istungite protokollid, mis on toimunud vahemikus 01.01.2020 ja 06.11.2023.
Joonis 15.1: Riigikogu istungite stenogrammid veebilehel
Kõik protokollid on Moodle’is praktikumi materjalide kaustas eraldi alamkaustas nimega stenogrammid2023.zip. Samuti on materjalide hulgas kraapimiseks kasutatud R-i skript.
Tänases ülesandes
- leiame, milliseid kohanimeüksusi on mingi istungi protokollis mainitud;
- analüüsime, milline on kohanimeüksust sisaldava tekstikatkendi meelsus: kas tekst on pigem positiivne, negatiivne või neutraalne;
- puhastame andmestiku;
- geokodeerime kohanimeüksused;
- visualiseerime andmeid.
15.1 Kohanimeüksuste ja tekstikatkendite meelsuse tuvastamine
Kohanimeüksuste automaatseks tuvastamiseks ning nende vahetu konteksti eraldamiseks tekstist kasutame EstNLTK analüüsivahendeid. Selleks, et Pythoni installimiselt ning skriptide kirjutamiselt aega kokku hoida, kasutame praktikumis Google Colabi, mille kaudu saame jooksutada juba valmis kirjutatud skripti. Kui soovid eesti keele automaattöötluse kohta rohkem õppida, on suureks abiks EstNLTK õppematerjalid (kaustas tutorials) ja TÜ kursus “Eesti keele töötlus Pythonis”.
Meelsusanalüüsiks kasutame siin Eesti Keele Instituudi emotsioonidetektorit, mille aluseks olev Pythoni kood on üleval GitHubi lehel https://github.com/EKT1/valence/. Sama kausta materjalid on ka Moodle’is failis valence-master.zip. Emotsioonidetektori kohta saad lugeda artiklist Pajupuu, Hille; Altrov, Rene; Pajupuu, Jaan (2016). Identifying polarity in different text types. Folklore. Electronic Journal of Folklore, 64, 25−42.
Koodi jooksutamiseks vajuta koodiplokkide vasakus servas oleval noolekesel. Kui midagi skripti jooksutamisel ei tööta, on praktikumi materjalides kaasas ka ühe näidisfaili (202106091400.csv) analüüsid (kaustas kohanimed_valmis).
| kohanime_vorm | kohanime_lemma | kontekst | meelsus |
|---|---|---|---|
| Eestis | Eesti | esmaspäeval kinnitasime nädala töökava ja sinna hulka oli märgitud ka Sotsiaaldemokraatliku Erakonna fraktsiooni algatatud olulise tähtsusega riikliku küsimuse ” Ebavõrdsus Eestis – kas vaesusest saab välja kärpida ? ” arutelu . Ettekandjaks oli määratud majandusanalüütik Madis Aben . Me teame . | positive |
| Viljandimaalt | Viljandimaa | oleks mõeldav ? Sest inimestele peab ju ette ka ütlema . Näiteks üks esineja peaks sel juhul hakkama siia sõitma Viljandimaalt . Aitäh ! Möönan , et olukord ei ole väga selge , just esinejate vaatest , aga me saame üheskoos | positive |
| Eestis | Eesti | tagasi hea kolleegi Helmen Küti ettepaneku juurde . Asjaolu , et on nad pannud püsti sellise küsimuse nagu ” Ebavõrdsus Eestis – kas vaesusest saab välja kärpida ? ” arutelu , on iseenesest nii verbaalses mõttes äärmiselt oluline kui ka sisu | positive |
| Eestis | Eesti | muud selgitust ma ei taha , ainult seda , mis annab õiguse – Sotsiaaldemokraatliku Erakonna päevakorda pandud punkti ” Ebavõrdsus Eestis ” välja arvata ! Palun nimetage see norm ! Härra Grünthal , Riigikogu juhatus ei arva Sotsiaaldemokraatliku Erakonna fraktsiooni päevakorrapunkti | positive |
| Euroopa | Euroopa | ole protseduuriline küsimus . Läheme edasi tänase päevakorraga . Esimene päevakorrapunkt on väliskomisjoni esitatud Riigikogu otsuse ” Riigikogu otsuse ” Euroopa Julgeoleku- ja Koostööorganisatsiooni Parlamentaarse Assamblee Eesti delegatsiooni moodustamine ” muutmine ” eelnõu esimene lugemine . Ettekande teeb väliskomisjoni liige Imre | neutral |
| Eesti | Eesti | tänase päevakorraga . Esimene päevakorrapunkt on väliskomisjoni esitatud Riigikogu otsuse ” Riigikogu otsuse ” Euroopa Julgeoleku- ja Koostööorganisatsiooni Parlamentaarse Assamblee Eesti delegatsiooni moodustamine ” muutmine ” eelnõu esimene lugemine . Ettekande teeb väliskomisjoni liige Imre Sooäär . Palun ! Aitäh , | neutral |
Skripti väljundiks on fail istung.csv, kus on tabelkujul
- kohanimeüksus sellisel kujul, nagu see tekstis esineb (tulp
kohanime_vorm);
- kohanimeüksuse algvorm (tulp
kohanime_lemma), mitmesõnalise kohanimeüksuse puhul on lemmatiseeritud ainult nimeüksuse viimane sõna (ntTallinna linn);
- kontekst ehk 20 sõna kohanimest vasakule ja paremale (tulp
kontekst);
- kontekstile määratud meelsuse hinnang (tulp
meelsus).
Loeme tabeli Excelisse või muusse tabeltöötlusprogrammi:
- Data → From Text/CSV → File Origin: UTF-8, Delimiter: Tab → Transform Data → vajuta Use First Row as Headers → Close & Load).
Hindame nimetuvastuse kvaliteeti. On teada, et automaatne nimetuvastus töötab kõige paremini isikunimede tuvastamisega, kohanimede ja organisatsioonidega on sel rohkem raskusi.
Võime andmeid pisut käsitsi puhastada ja korrastada. Kustutame tabelist read, kus nimetuvastus on eksinud (nt Facebook, Euroopa Liit), parandame kohanimede lemmasid (nt pai → Paide).
Salvestame Exceli tabeli nimega istung.xlsx.
15.2 Tekstikatkendi meelsuse tuvastamine Excelis
EKI emotsioonidetektor on tegelikult kasutatav ka MS Exceli laiendusena (Add-in), ent see ei pruugi uuemates Exceli versioonides alati töötada. Katsetame.
- Laadime lehelt http://peeter.eki.ee:5000/applications/list alla faili valence.xlam.
- Otsime Excelist üles File → Options → Add-ins → Manage Excel Add-ins → Go → Browse, otsime üles faili valence.xlam.
- Kirjutame Excelis tabeli uude tulpa
=Valence.TestBayes()ja sulgude vahele lahtri viite, milles on tekst (nt=Valence.TestBayes(C2)). Kontrollime, kas tulemused vastavad Pythoni skriptiga saadud tulemustele.
15.3 Koordinaatide lisamine (geokodeerimine)
Nüüd peame saama oma tabelile koordinaadid. Selleks võiksime proovida põhimõtteliselt kasutada ka Maa-ameti geokodeerimise teenust, aga kuna teame, et meie tabelis on palju ka välisriikide kohanimesid, ei oleks sellest väga palju kasu. Katsetame niisiis hoopis QGISi geokodeerijat.
Esmalt salvestame xlsx-faili csv-na, nt nimega istung_parandatud.csv. Geokodeerimise jaoks oleks vaja, et faili kodeering oleks UTF-8.
Seejärel
- avame QGISi,
- otsime sobiva aluskaardi ja CRS-i,
- laadime csv-faili QGISi,
- valime Processing → Toolbox → Vector general → Batch Nominatim geocoder, Input layer on csv-faili kiht, mille just laadisime, Address field on kohanime_lemma.
Joonis 15.2: Tuvastatud kohanimede geokodeerimine QGISis
Nimetame kihi Geocoded ümber nimega istungi_kohad.
15.4 Visualiseerimine
Mainimiste arv
Vaatame esmalt, milliseid kohti ja kui palju mainiti. Selleks on teatavasti mitu võimalust:
- muudame punktide läbipaistvust (rohkem mainitud kohad jäävad tumedamalt);
- valime Symbology jaotises Single symbol asemel Point Cluster või Point Displacement;
- valime Symbology jaotises Heatmap, valime sobiva värvipaleti ja -skaala.
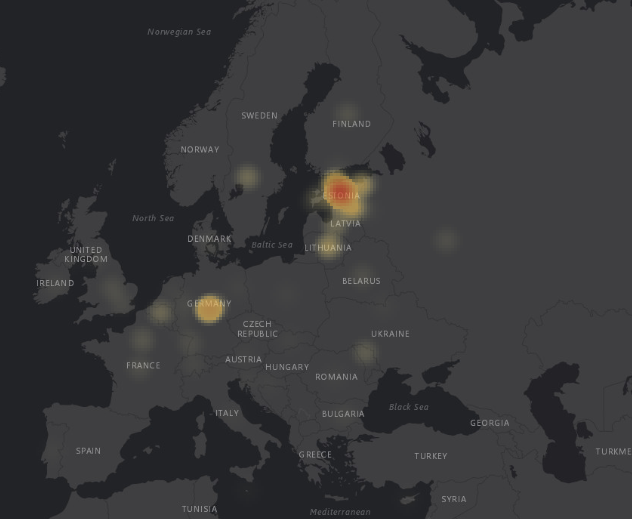
Joonis 15.3: Stenogrammis mainitud kohanimede heatmap
Võime ka teha uue kihi, kus loeme kokku, kui mitu korda üht nime mainitakse, ja visualiseerida mainimiste arvu näiteks punkti suuruse abil. Selleks valime Database → DB Manager → SQL Window ja päringu aknasse kirjutame
SELECT kohanime_lemma, COUNT(kohanime_lemma) AS arv, geometry
FROM istungi_kohad
GROUP BY kohanime_lemma;Vajutame Execute, teeme linnukese kasti Load as new layer ette ja vajutame Load. Uuel kihil vajutame Size paremas ääres kastikest, valime Expression → Edit ja kirjutame avaldiseks log10("arv")*10. Logaritmimine vähendab erinevusi suurt arvude vahel ja toob esile erinevusi väiksemate arvude vahel.
Emotsioonid
Kasutame punktide asemel diagramme, et visualiseerida, kui suur protsent mingi koha mainimistest olid positiivses, negatiivses ja neutraalses kontekstis. Selleks tuleb esmalt teha kiht, kus oleme kokku lugenud iga koha iga emotsiooni mainimiste arvu ja pannud selle eraldi tulpadesse.
Database → DB Manager → SQL Window ja päringu aknasse kirjutame
SELECT kohanime_lemma, geometry,
SUM(CASE WHEN meelsus = 'positive' THEN 1 ELSE 0 END) AS positive,
SUM(CASE WHEN meelsus = 'negative' THEN 1 ELSE 0 END) AS negative,
SUM(CASE WHEN meelsus = 'neutral' THEN 1 ELSE 0 END) AS neutral
FROM istungi_kohad
GROUP BY kohanime_lemma; - Uue tekkinud kihi Symbology jaotises valime Single symbol asemel No symbols.
- Lisame pirukadiagrammid (Diagrams → Pie Chart),
- atribuutideks valime tulbad positive, negative ja neutral,
- neile kategooriatele valime sobivad värvid,
- muudame diagrammid veidi läbipaistvamaks (Rendering → Opacity)
- ja diagrammide suuruseks määrame Scaled size,
- Attribute väärtuseks
"positive"+"negative"+"neutral"
- ja valime sobiva skaala, arvestades kõige sagedamini mainitud koha mainimiste arvu ja kõige harvemini mainitud kohtade arvu.
- Attribute väärtuseks
- paneme diagrammid punktide koha peale: Placement → Over point.
- atribuutideks valime tulbad positive, negative ja neutral,
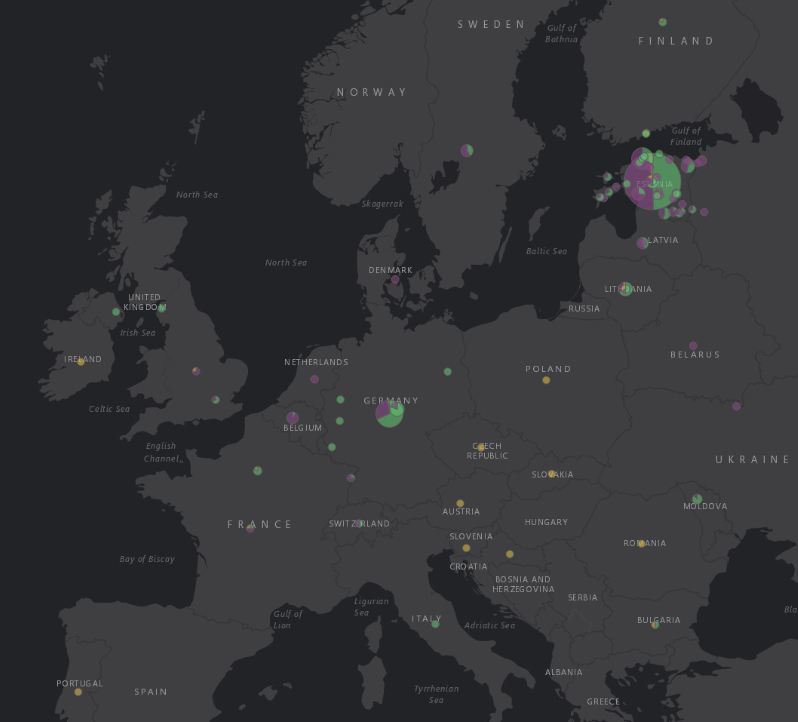
Joonis 15.4: Positiivsete, negatiivsete ja neutraalsete mainimiste osakaalud
Teine variant sama tulemuseni jõudmiseks oleks
- teha topeltklikk kihil istungi_kohad,
- kaotada Symbology jaotises ära tavalised punktikesed (No symbols),
- jaotises Diagrams valida Pie Chart,
- seal omakorda Attributes jaotises lisada Assignes attributes aknasse kolm avaldist, mis loeksid kokku iga kohanime lemma esinemiskorrad juhul, kui 1) meelsuse tulbas on väärtus positive, 2) meelsuse tulbas on väärtus negative, 3) meelsuse tulbas on väärtus neutral:
count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='positive')
count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='negative')
count("kohanime_lemma", group_by:="kohanime_lemma", filter:="meelsus"='neutral')
- diagrammide Size jaotises valida Scaled size → Attribute väärtuseks kirjutada avaldis
count("kohanime_lemma", group_by:="kohanime_lemma"), Maximum value määrata Find nupu abil, Size väärtuseks määrata nt 15 ning suurendada ka väikeste diagrammide suurust (nt 2 peale).
Sellisel juhul aga tuleb iga muudatust tehes (nt sektorite värvi, diagrammide suurust, läbipaistvust vm-d muutes) diagrammide aluseks olevad andmed iga kord uuesti genereerida ning seetõttu võtab muudatuste nägemine kauem aega.
Määrame lõpuks ka kohanimedele sildid, mis tuleksid nähtavale alles siis, kui oleme piisavalt sisse suuminud.
Symbology → Labels → Single labels → Rendering → Scale Dependent Visibility. Vali ka Overlapping labels → Allow Overlaps without Penalty.